Plots for groups of objects
The package has another method for creating plots, mdaplotg(), which aims at making plots for groups of objects. It can be several groups of points, lines or bars, where every group has its own attributes, such as color, marker, line type and width, etc. There is a simple criterion to distinguish between the simple and group plots: group plots usually need a legend and simple plots — not. The mdaplotg() method allows one to do a lot of things (e.g. split data into groups, add a legend and labels, etc) much easier and this section will show most of the details.
There are three ways to provide data sets for making the group plots. Let’s discuss them first and then talk about some extra features.
One matrix or data frame
If the dataset is a matrix or a data frame, mdaplotg() will make a line, scatter-line or a bar plot, considering every row as a separate group. This can be useful, when, for example, you want to show how explained variance depends on a number of components for calibration and test set, or how loadings for the first two components look like.
If you want to change any parameters, like pch, lty, lwd, col or similar you need to provide either a vector with values for each group or one value for all groups. Axis limits, ticks, ticklabels, etc. can be defined similarly to the simple plots. Here are some examples.
# let's create a simple dataset with 3 rows
p = rbind(
c(0.40, 0.69, 0.88, 0.95),
c(0.34, 0.64, 0.81, 0.92),
c(0.30, 0.61, 0.80, 0.88)
)
# add some names and attributes
rownames(p) = c("Cal", "CV", "Test")
colnames(p) = paste0("PC", 1:4)
attr(p, "name") = "Cumulative variance"
attr(p, "xaxis.name") = "Components"
# and make group plots of different types
par(mfrow = c(2, 2))
mdaplotg(p, type = "l")
mdaplotg(p, type = "b")
mdaplotg(p, type = "h", xticks = 1:4)
mdaplotg(p, type = "b", lty = c(1, 2, 1), col = c("red", "green", "blue"), pch = 1,
xticks = 1:4, xticklabels = colnames(p))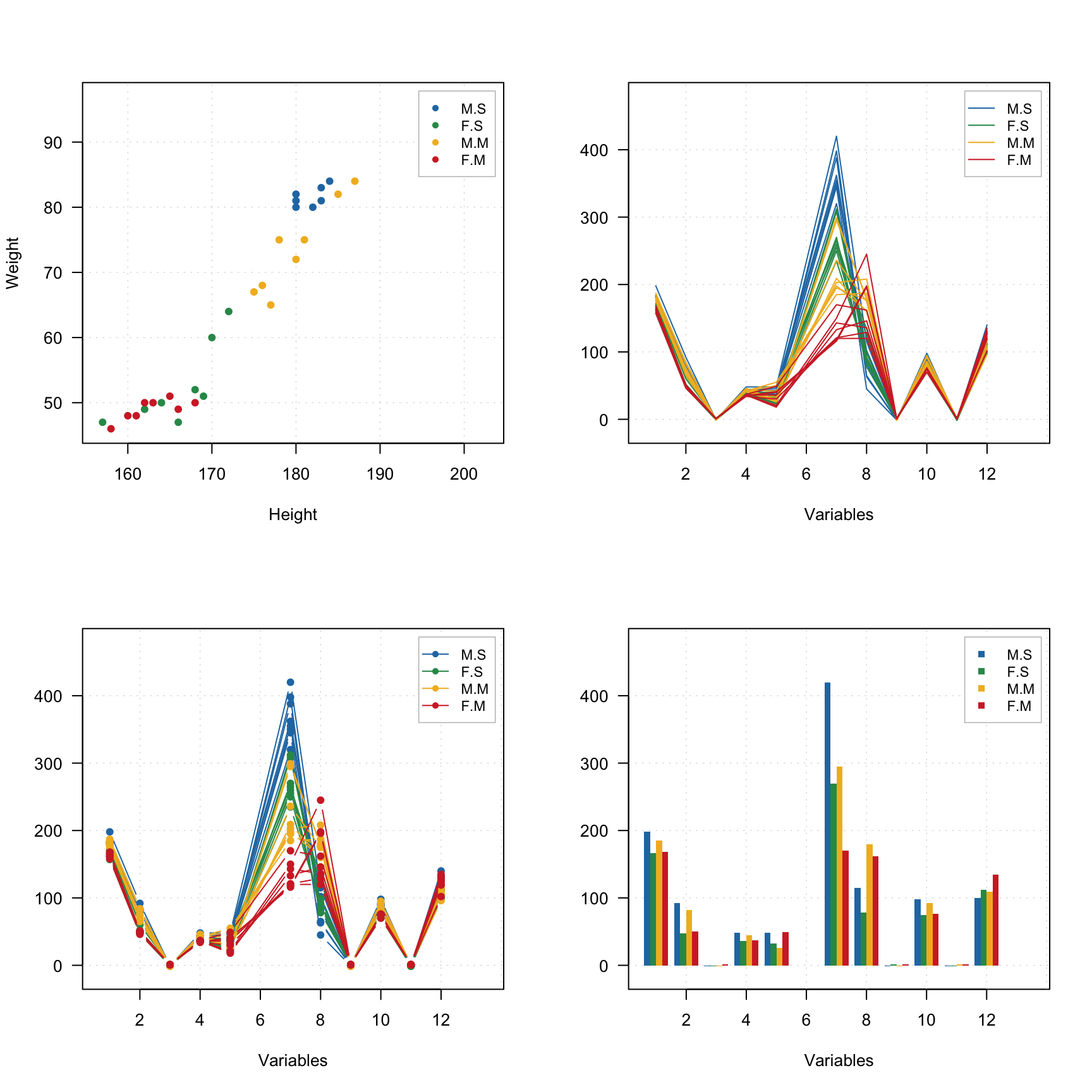
As you can see, mdaplotg() automatically created the legend and set colors, line parameters, etc. correctly. You can change position of the legend using same names as for basic legend() command from R, or hide it using parameter show.legend = FALSE, as it is shown below.
par(mfrow = c(2, 2))
mdaplotg(p, type = "l", legend.position = "top")
mdaplotg(p, type = "b", legend.position = "bottomleft")
mdaplotg(p, type = "h", legend.position = "bottom")
mdaplotg(p, type = "b", show.legend = FALSE)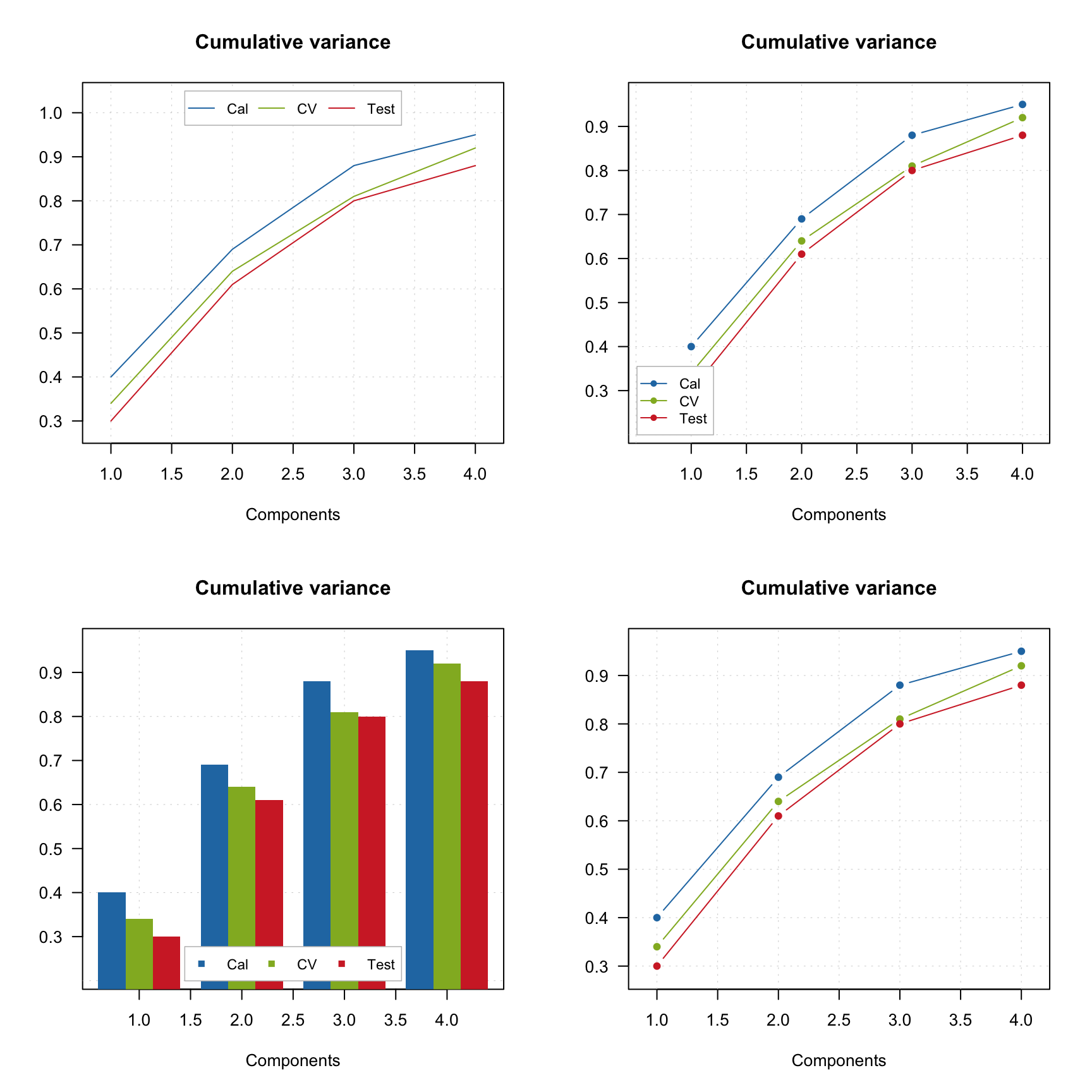
Group plots also allow you to show labels, in this case they can be either values, names or indices of the columns.
par(mfrow = c(2, 2))
mdaplotg(p, type = "l", show.labels = TRUE)
mdaplotg(p, type = "b", show.labels = TRUE, labels = "indices")
mdaplotg(p, type = "h", show.labels = TRUE, labels = "values")
mdaplotg(p, type = "b", show.labels = TRUE, labels = "values")
List with matrices or data frames
In this case every element of the list will be treated as a separate group. This way allows you to make scatter plots as well as line plots with several lines in each group. Bar plot can also be made but in this case the first row from each dataset will be used. If you use names when creating the list, the names will be taken as legend labels, otherwise the method will look at the attribute "name" for each dataset.
In the example below we split People data to males and females and show the group plots.
# load data and exclude column with income
data(people)
people = mda.exclcols(people, "Income")
# use values of sex variable to split data into two subsets
sex = people[, "Sex"]
m = mda.subset(people, subset = sex == -1)
f = mda.subset(people, subset = sex == 1)
# combine the two subsets into a named list
d = list(male = m, female = f)
# make plots for the list
par(mfrow = c(2, 2))
mdaplotg(d, type = "p")
mdaplotg(d, type = "b")
mdaplotg(d, type = "h")
mdaplotg(d, type = "b", lty = c(1, 2), col = c("red", "blue"), pch = 1)
Most of the things described in the previous subsection will work similarly for this case. We will just add a bit more details on how labels and excluded rows are processed for the scatter plots. By default labels are row names or indices. In mdaplotg() you cannot provide a vector with manual values, so the best way to change them is to assign them as the row names. Indices are unique within each group, so if you have, e.g. three groups of points, there will be three points with index “1”, three with “2”, etc.
Use factors to split a dataset into groups
One more way to split a dataset into groups is to provide one or several factor columns using argument groupby. In this case mdaplotg() will find all combinations of the factor levels and split rows of the dataset into the corresponding groups. In the example below we use variables Region and Sex to make plots for four groups.
It is assumed that you already loaded the People data (from previous examples) and excluded the Income column.
sex = factor(people[, "Sex"], labels = c("M", "F"))
reg = factor(people[, "Region"], labels = c("S", "M"))
groups = data.frame(sex, reg)
par(mfrow = c(2, 2))
mdaplotg(people, type = "p", groupby = groups)
mdaplotg(people, type = "l", groupby = groups)
mdaplotg(people, type = "b", groupby = groups)
mdaplotg(people, type = "h", groupby = groups)
All parameters, described before, will work the same way in this case.